并查集的基本操作
并查集是一种由不相交集合组成的数据结构,它可以用 表示,其中 是由若干元素组成的集合,任意两个集合之间的交集都为 ,每个集合都有一个元素作为它的代表。
并查集需要支持以下操作:
MAKE-SET(x)创建一个仅含 x 的新集合(x 不得同时属于其他集合)UNION(x,y)将集合 x、y 合并到一起,形成新的集合FIND-SET(x)返回集合 x 的代表
一般来说,每个元素都会先通过 MAKE-SET 形成只包含自己的集合,然后通过 UNION 相互兼并。MAKE-SET 和 UNION的运行次数是有限的,不会超过所有元素的总数 。与此同时,外部会通过FIND-SET查询某个元素当前属于哪个集合,该操作的次数没有上限。所以,一个并查集的运行效率可以通过两个变量衡量——MAKE-SET 的运行次数 ,以及上述所有三种操作的总次数 。这里假设了每个元素都会先形成自己的集合。
**并查集的应用举例:**有若干个结点,一开始是互相分开的(相当于各自 MAKE-SET),现在要在它们之间加入无向边(相当于 UNION),并且随时查询当前某两个结点之间是否存在一条路径(相当于判断 FIND-SET 的结果是否相同)。
并查集的链表实现
用一个 dummy 作为链表头以及集合代表,串起集合的所有元素,让它们都有一个指针指向 dummy(便于 FIND-SET),同时 dummy 还记录着链表尾部的位置(便于插入元素)。
MAKE-SET 和 FIND-SET 的实现自不必说,都只需要常数时间。UNION 需要遍历一个集合的所有元素,依次插入另一个集合的尾部,时间正比于前者的元素个数。最坏情况下,用 次 UNION 合并 个独立元素需要 时间。
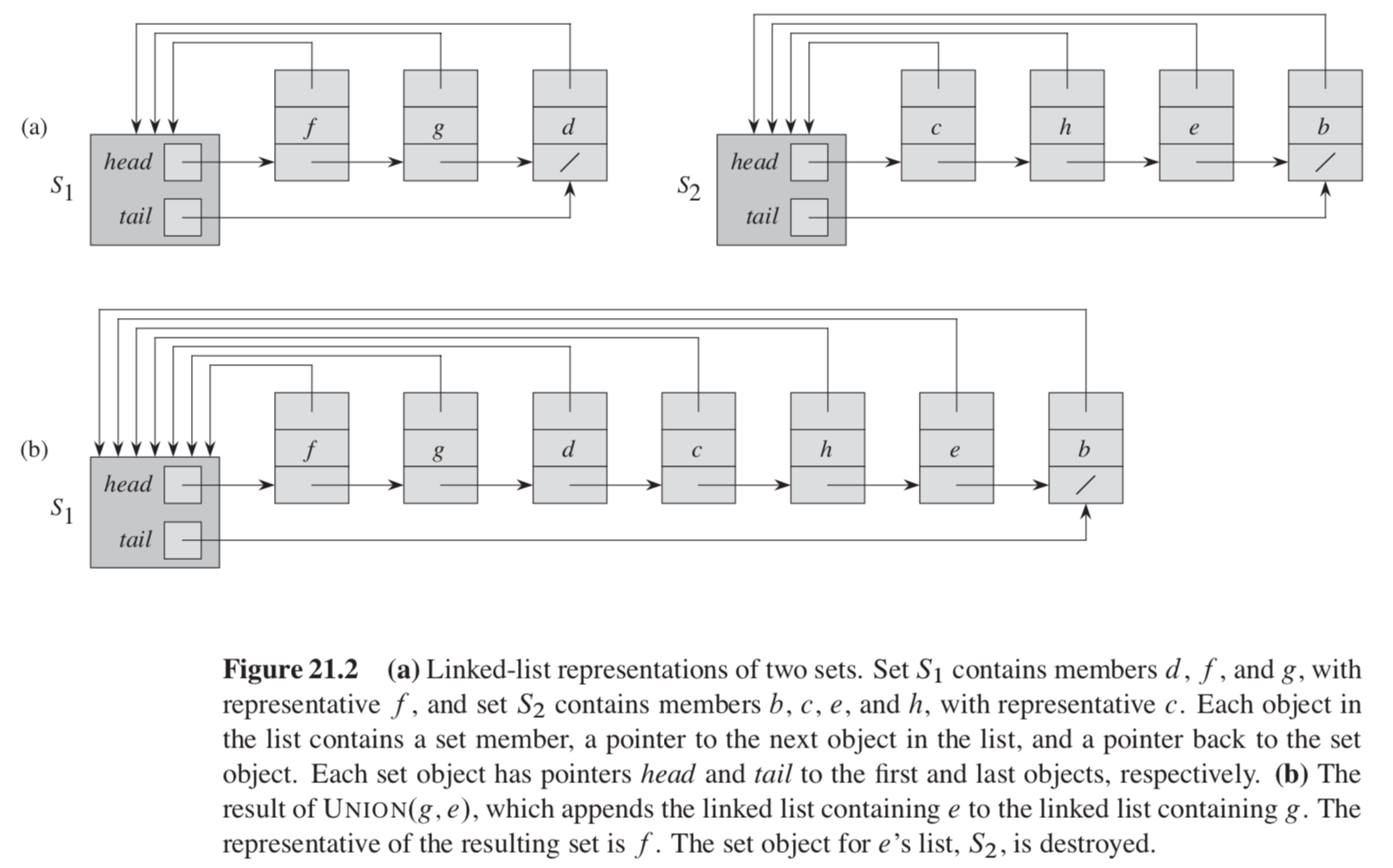
为了优化时间,我们可以在 dummy 记录每个集合的元素个数,然后每次 UNION 时都让更小的集合并入更大的集合。
定理:用上述方法实现的并查集,操作时间为
证明:
UNION 重复地将一个集合的元素移动至另一个集合链表的末尾,这样的移动次数决定了它的时间复杂度。对于任意一个元素,当它被移动到另一个集合中去时,它都属于更小的那个集合。也就是说,它所属集合的大小会在移动后至少翻倍。由于集合大小不会超过 ,所以它最多被移动 次,所以UNION的时间复杂度是 。
MAKE-SET 和 FIND-SET 只需常数时间,所以三种操作总的时间复杂度是 。
并查集的森林实现
把每个集合的元素组织成一棵有根树,根作为集合的代表,每个结点只保存父亲的位置(根的父亲指向自己)。那么 MAKE-SET 相当于创造一棵单结点树,FIND-SET 相当于从结点向上追溯到根,UNION 相当于把一棵树作为另一棵树的子树。
如果不加限制地用上面的方法实现并查集,其效率不比链表实现好多少。书中介绍了两个提升效率的办法:
1. Union by rank,为每个结点记录一个属性值 rank,表示它的“高度上限”。如果集合只包含自己,那么rank就是0;两个集合合并时,选择 rank 较低的树并入 rank 较高的树;若两者rank相等,则接受另一棵树的根结点 rank 加1(因为它现在有一个高度最多为 rank 的儿子,所以自己的高度最多为 rank + 1)。这和之前链表实现的思路类似,可以控制树的高度。 2. Path compression,每次 FIND-SET 的时候,让路过的结点都指向最终返回的根结点,从而削减树的高度。
伪代码如下:
MAKE-SET(x)
x.p = x
x.rank = 0
UNION(x,y)
LINK(FIND-SET(x), FIND-SET(y))
LINK(x,y)
if x.rank > y.rank
y.p = x
else x.p = y
if x.rank == y.rank
y.rank += 1
FIND-SET(x)
if x != x.p
x.p = FIND-SET(x.p)
return x.p
值得品味的是FIND-SET的递归结构。从上到下递归时,每一层的参数x都是上一层的父亲,直到最后一层返回root。从下到上返回时,每一层的 parent 指针都会被设为下一层的返回值,再返回给上一层。所以FIND-SET最终不仅会返回 root,并且从 x 到 root 的所有结点都会直接指向树根,从而实现了 path compression。
森林实现的时间复杂度是 ,其中 是一个增长极慢的函数,当 时其值不超过4,所以可以近似地看作常数。具体证明略(参见21-4小节)。
PS:单独使用 union by rank 的效果是 ,单独使用 path compression 的效果是 , 是FIND-SET的次数。(参见21-3小节)